Интернет магазин китайских планшетных компьютеров |
|
Компьютеры - PAQ16 июня 2011Оглавление: 1. PAQ 2. История 3. Результаты тестов серия свободных архиваторов с текстовым интерфейсом, которые общими усилиями разработчиков поднялись в первые места рейтингов многих тестов сжатия данных. Лучший результат в этой серии на большинстве тестов был получен архиватором PAQ8JD, созданным совместными усилиями Мэтта Махони, Александра Ратушняка, Сергея Оснача, Пшемыслава Скибиньского и Билла Петтиса, и выпущенным 30 декабря 2006 года. Однако, в некоторых тестах он отстаёт от WinRK в режиме PWCM. PWCM — сторонняя проприетарная реализация алгоритма PAQ. Специально настроенные версии алгоритма PAQ выиграли призы в Приз Хаттера и Калгари Корпус Челлендж. АлгоритмВ основе алгоритма лежит идея контекстного моделирования. Контекст — это, говоря доступным языком, история появления символа, то есть, информация о символах, предшествующих текущему в сжимаемом потоке. При этом процесс компрессии разбивается на две фазы: моделирование и кодирование. PAQ использует алгоритм смешивания контекстов. Смешивание контекстов — это техника, тесно связанная с алгоритмом PPM, но отличие состоит в том, что вероятность появления следующего символа вычисляется на основе взвешенной комбинации большого числа моделей, зависящих от разных контекстов, не обязательно следующих друг за другом. В PAQ семействе для сбора статистики и предсказания вероятности следующего символа используются в основном следующие модели:
Все версии PAQ предсказывают и сжимают за раз один бит, но различаются в деталях реализации того, как предсказания комбинируются и обрабатываются после. Как только предсказательно была определена вероятность появления следующего бита, бит сжимается арифметическим кодером. Существует три способа для комбинирования предсказаний моделей в зависимости от версии PAQ.
PAQ1SSE и позднейшие версии использовали пост-обработку предсказания методом вторичной оценки символа, то есть, комбинированное предсказание и небольшой контекст использовались для выбора следующего предсказания по таблице. После того, как символ был закодирован, данные в таблице корректировались для уменьшения ошибки предсказания. Вторичная оценка символа может быть объединена в один процесс с разными контекстами либо может выполняться параллельно, усредняясь с выходами моделей. Арифметическое кодированиеСтрока s сжимается в байтовую строку, представляющую число x в 256-значной системе исчисления big endian в интервале [0;1), такое, что P ≤ x < P, где P - вероятность что случайная строка r такой же длины как s лексикографически меньше чем s. Всегда возможно найти такую строку x, что длина её хотя бы на один байт превосходит лимит Шеннона: -log2 P бит. Длина s сохраняется в заголовке архива. Арифметический кодер в PAQ реализован путём хранения верхней и нижней границ x для каждого шага предсказания, начально [0;1). После каждого предсказания текущий интервал делится пропорционально вероятностям того, что следующий бит будет 0 и следующий бит будет 1, на основании предыдущих битов s. Следующий бит кодируется, выбирая соответствующий подынтервал как новый интервал. Число x декомпрессируется в строку s идентичной серией битовых предсказаний. Интервал делится как при сжатии. Часть, содержащая x, становится новым интервалом, и соответствующий бит добавляется к s. В PAQ верхняя и нижняя границы интервала представляются тремя частями. Наиболее значимые разряды по основанию 256 идентичны, так они могут быть записаны как старшие байты x. Следующие 4 байта хранятся в памяти так, что старший байт различается. Младшие биты подразумеваются все нулями для нижней границы и все единицами для верхней границы. Кодирование завершается записью ещё одного байта из нижней границы. Адаптивное Взвешивание МоделейВ PAQ версиях до PAQ6 каждая модель отображала множество различных контекстов на пару счётчиков: n0 — количество нулевых битов и n1 — количество единичных битов. Для увеличения значимости более поздней истории битов счётчик уменьшался почти вдвое, когда противоположный бит встречался. Например, текущее состояние модели, ассоциированное с контекстом = и бит 1 наблюдается на входе — счётчик обновляется до состояния. Бит сжимается арифметическим кодером соответственно его вероятности либо P либо P=1-P. Вероятности вычисляются взвешенным суммированием счётчиков нулей и единиц:
где wi вес i-той модели. До PAQ3 веса были фиксированными и устанавливались в случайном порядке. Начиная с PAQ4, веса выбирались адаптивно в направлении уменьшения ошибки предсказания в одинаковых наборах контекстов. Если требуется закодировать бит y, то веса назначаются следующим образом:
Нейронные сети для смешиванияНачиная с PAQ7, выходом каждой модели является предсказание. Предсказания усредняются в логистическом домене по формуле:
где P — вероятность того, что следующий бит будет единицей, а Pi — вероятность, оцененная i- моделью и
После каждого предсказания модель обновляется выравниванием весов для уменьшения цены сжатия.
где η — коэффициент обучения, y — предсказанный бит и) — ошибка предсказания. Алгоритм обновления весов отличается от привычного в нейронных сетях обучающего метода обратного распространения ошибки в том, что произведение PP не учитывается, потому что цель нейронной сети — минимизация стоимости кодирования, а не среднеквадратичной ошибки. Большинство версий PAQ используют небольшой контекст при выборе набора весов для нейронной сети. Некоторые версии используют двух- и трёхшаговые предсказатели, состоящие из соответственно двух или трёх множеств нейронных сетей, выход каждой предыдущей является входом для следующего множества сетей, мощность которого меньше, и затем следует вторичная оценка символа. Более того, для каждого входящего предсказания может быть несколько входов, являющихся нелинейными функциями Pi в дополнение к сжать). Контекстное моделированиеКаждая модель разделяет входящий поток бит s на множество контекстов и отображает каждый контекст на состояние истории битов, представленное 8 битами. В версиях до PAQ6 состояние было представлено парой счётчиков. В PAQ7 и более поздних состояние содержало при определённых условиях также последний бит или целую последовательность. Значения состояний отображаются в вероятности, используя 256-значную таблицу. После табличного предсказания значение в таблице немного выравнивалось для уменьшения погрешности предсказания. Во всех PAQ8 версиях состояния истории битов содержат следующую информацию:
Чтобы сохранить количество состояний равным 256, следующие ограничения были наложены на счётчики:,,,,,,,,. Если счётчик превышает лимит, следующее состояние выбирается с подобным соотношением n0 / n1. Таким образом, если текущее состояние и 1 получена на входе, тогда новое состояние не, а. Большинство контекстных моделей реализованы как хэш-таблицы. Некоторые небольшие контексты реализованы как индексные массивы. Предварительная обработка текстаНекоторые версии PAQ, в особенности PAsQDAa,PAQAR, и от PAQ8HP1 до PAQ8HP8 обрабатывают текст, просматривая его и заменяя слова из текста, содержащиеся во внешнем словаре одно- трёх-байтными кодами. Дополнительно слова в верхнем регистре кодируются специальным символом и переводом слова в нижний регистр. В PAQ8HP серии словарь организован группировкой синтаксически и семантически похожих слов вместе. Это позволяет использовать модели, которые используют только верхние биты словарных кодов в качестве контекстов. Просмотров: 3530
|
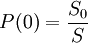
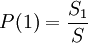
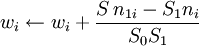 ошибка
ошибка