Интернет магазин китайских планшетных компьютеров |
|
Компьютеры - Оптимизация (информатика) - Простейшие приёмы оптимизации программ по затратам процессорного времени24 февраля 2011Оглавление: 1. Оптимизация (информатика) 2. Основы 3. Простейшие приёмы оптимизации программ по затратам процессорного времени 4. Приоритеты оптимизации Оптимизация по затратам процессорного времени особенно важна для расчетных программ, в которых большой удельный вес имеют математические вычисления. Здесь перечислены некоторые приемы оптимизации, которые может использовать программист при написании исходного текста программы. Инициализация объектов данныхВо многих программах какую-то часть объектов данных необходимо инициализировать, то есть присвоить им начальные значения. Такое присваивание выполняется либо в самом начале программы, либо, например, в конце цикла. Правильная инициализация объектов позволяет сэкономить драгоценное процессорное время. Так, например, если речь идет об инициализации массивов, использование цикла, скорее всего, будет менее эффективным, чем объявление этого массива прямым присвоением. Программирование арифметических операцийВ том случае, когда значительная часть времени работы программы отводится арифметическим вычислениям, немалые резервы повышения скорости работы программы таятся в правильном программировании арифметических выражений. Важно, что различные арифметические операции значительно различаются по быстродействию. В большинстве архитектур, самыми быстрыми являются операции сложения и вычитания. Более медленным является умножение, затем идёт деление. Например, вычисление значения выражения ; Исходный операнд в регистре EAX ADD EAX, EAX ; умножение на 2 LEA EAX, ; умножение на 3 SHL EAX, 2 ; умножение на 4 LEA EAX, ; другой вариант реализации умножения на 4 LEA EAX, ; умножение на 5 LEA EAX, ; умножение на 6 ADD EAX, EAX ; и т.д.
Относительно много времени тратится на обращение к подпрограммам. Если подпрограмма содержит малое число действий, она может быть реализована подставляемой — все ее операторы копируются в каждое новое место вызова. Это ликвидирует накладные расходы на обращение к подпрограмме, однако ведет к увеличению размера исполняемого файла. Само по себе увеличение размера исполняемого файла не является существенным, однако в некоторых случаях исполняемый код может выйти за пределы кэша команд, что повлечет значительное падение скорости исполнения программы. Поэтому современные оптимизирующие компиляторы обычно имеют настройки оптимизации по размеру кода и по скорости выполнения. Быстродействие также зависит и от типа операндов. Например, в языке Turbo Pascal, ввиду особенностей реализации целочисленной арифметики, операция сложения оказывается наиболее медленной для операндов типа Программируя арифметические выражения, следует выбирать такую форму их записи, чтобы количество «медленных» операций было сведено к минимуму. Рассмотрим такой пример. Пусть необходимо вычислить многочлен 4-й степени:
При условии, что вычисление степени производится перемножением основания определенное число раз, нетрудно найти, что в этом выражении содержится 10 умножений и 4 сложения. Это же самое выражение можно записать в виде:
Такая форма записи называется схемой Горнера. В этом выражении 4 умножения и 4 сложения. Общее количество операций сократилось почти в два раза, соответственно уменьшится и время вычисления многочлена. Подобные оптимизации являются алгоритмическими и обычно не выполняется компилятором автоматически. ЦиклыРазличается и время выполнения циклов разного типа. Время выполнения цикла со счетчиком и цикла с постусловием при всех прочих равных условиях совпадает, цикл с предусловием выполняется несколько дольше. При использовании вложенных циклов следует иметь в виду, что затраты процессорного времени на обработку такой конструкции могут зависеть от порядка следования вложенных циклов. Например, вложенный цикл со счетчиком на языке Turbo Pascal:
Цикл в левой колонке выполняется примерно на 10 % дольше, чем в правой. На первый взгляд, и в первом, и во втором случае 10 000 000 раз выполняется оператор присваивания, и затраты времени на это должны быть одинаковы в обоих случаях. Но это не так. Объясняется наше наблюдение тем, что инициализации цикла, то есть обработка процессором его заголовка с целью определения начального и конечного значений счётчика, а также шага приращения счётчика требует времени. В первом случае 1 раз инициализируется внешний цикл и 100 000 раз — внутренний, то есть всего выполняется 100 001 инициализация. Во втором случае, как нетрудно подсчитать, таких инициализаций оказывается всего лишь 1001. Аналогично ведут себя вложенные циклы с предусловием и с постусловием. Можно сделать вывод, что при программировании вложенных циклов по возможности следует делать цикл с наибольшим числом повторений самым внутренним, а цикл с наименьшим числом повторений — самым внешним.
Если в циклах содержатся обращения к памяти, порядок обхода адресов памяти должен быть по возможности последовательным, что позволяет максимально эффективно использовать кэш и механизм аппаратной предвыборки данных из памяти. Классическим примером подобной оптимизации является смена порядка следования вложенных циклов при выполнении умножения матриц. При вычислении сумм часто используются циклы, содержащие одинаковые операции, относящиеся к каждому слагаемому. Это может быть, например, общий множитель:
Очевидно, что вторая форма записи цикла оказывается более экономной. Инвариантные фрагменты кодаОптимизация инвариантных фрагментов кода тесно связана с проблемой оптимального программирования циклов. Внутри цикла могут встречаться выражения, фрагменты которых никак не зависят от управляющей переменной цикла. Их называют инвариантными фрагментами кода. Современные компиляторы часто определяют наличие таких фрагментов и выполняют их автоматическую оптимизацию. Такое возможно не всегда, и иногда производительность программы зависит целиком от того, как запрограммирован цикл. В качестве примера рассмотрим следующий фрагмент программы:
for i := 1 to n do
begin
...
for k := 1 to p do
for m := 1 to q do
begin
a := Sqrt + Abs;
b := Sin + Abs;
end;
...
am := 0;
bm := 0;
for k := 1 to p do
for m := 1 to q do
begin
am := am + a / c;
bm := bm + b / c;
end;
end;
Здесь инвариантными фрагментами кода являются слагаемое Просмотров: 3927
|
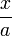 , где a — константа, для аргументов с плавающей точкой производится быстрее в виде
, где a — константа, для аргументов с плавающей точкой производится быстрее в виде 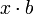 , где
, где 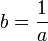 — константа, вычисляемая на этапе компиляции программы. Для целочисленного аргумента x вычисление выражения 2x быстрее произвести в виде x + x или с использованием операции сдвига влево. Подобные оптимизации называются понижением силы операций. Умножение целочисленных аргументов на константу на процессорах семейства x86 может быть эффективно выполнено с использованием ассемблерных команд
— константа, вычисляемая на этапе компиляции программы. Для целочисленного аргумента x вычисление выражения 2x быстрее произвести в виде x + x или с использованием операции сдвига влево. Подобные оптимизации называются понижением силы операций. Умножение целочисленных аргументов на константу на процессорах семейства x86 может быть эффективно выполнено с использованием ассемблерных команд