Интернет магазин китайских планшетных компьютеров |
|
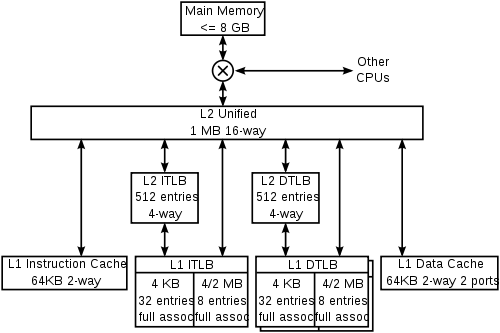
Компьютеры - Кэш процессора - Иерархия кэшей в современных микропроцессорах23 января 2011Оглавление: 1. Кэш процессора 2. Принцип работы 3. Структура записи в кэше 4. Виды промахов 5. Трансляция адресов 6. Иерархия кэшей в современных микропроцессорах 7. Реализации Большинство современных процессоров содержат в себе несколько взаимодействующих кэшей. Специализированные кэшиСуперскалярные ЦПУ осуществляют доступ к памяти из нескольких этапов конвейера: чтение инструкции, трансляция виртуальных адресов в физические, чтение данных. Очевидным решением является использование различных физических кэшей для каждого из этих случаев, чтобы не было борьбы за доступ к одному из физических ресурсов с разных стадий конвейера. Таким образом, наличие конвейера обычно приводит к наличию по крайней мере трёх раздельных кэшей: кэш инструкций, кэш трансляций TLB и кэш данных, каждый из которых специализирован на своей задаче. Конвейерные процессоры использующие раздельные кэши для данных и для инструкций называются имеющими Гарвардскую архитектуру. Изначально сей термин применялся для компьютеров, у которых инструкции и данные разделены полностью и хранятся в различных устройствах памяти. Однако, такое полное разделение не оказалось популярным, и большинство современных компьютеров имеют одно устройство основной памяти и поэтому могут считаться машинами с архитектурой фон Неймана Victim cacheVictim cache — это небольшой специализированный кэш, хранящий те кэш-линии, которые были недавно вытеснены из основного кэша микропроцессора при их замещении. Данный кэш располагается между основным кэшем и его refill path. Обычно кэш жертв является полностью ассоциативным и служит для уменьшения количества конфликтных промахов. Многие часто используемые программы не требуют полного ассоциативного отображения для всех попыток доступа к памяти. По статистике, только небольшая доля обращений к памяти потребует высокой степени ассоциативности. Именно для таких обращений служит кэш жертв, предоставляющий высокую ассоциативность для подобных редких запросов. Был внедрен Norman Jouppi в 1990. Trace cacheОдним из наиболее экстремальных случаев специализации кэшей можно считать trace cache, используемый в процессорах Intel Pentium 4. trace cache — это механизм для увеличения пропускной способности загрузки инструкций и для уменьшения тепловыделения за счет хранения декодированных трасс инструкций. Таким образом этот кэш исключал работу декодера при повторном исполнении недавно выполнявшегося кода. Одной из ранних публикацией о trace cache была статья Eric Rotenberg, Steve Bennett и Jim Smith в 1996 году под названием «Trace Cache: a Low Latency Approach to High Bandwidth Instruction Fetching.». Кэш трасс сохраняет декодированные инструкции либо после их декодирования либо после окончания их исполнения. Обобщая, инструкции добавляются в кэш трасс в группах, представляющих собой либо базовые блоки либо динамические трассы. Динамическая трасса состоит только из инструкций, результаты которых были значимы и удаляет инструкции, которые находятся в не исполняющихся ветвях, кроме того динамическая трасса может быть объединением нескольких базовых блоков. Такая особенность позволяет устройству подгрузки инструкций в процессоре загружать сразу несколько базовых блоков без необходимости заботиться о наличии ветвлений в потоке исполнения Линии трасс хранятся в trace cache по адресам, соответствующим счетчику инструкций первой машинной команды из трассы, к которым добавлен набор признаков предсказания ветвлений. Такая адресация позволяет хранить различные трассы исполнения, начинающиеся с одного адреса, но представляющие различные ситуации по результату предсказания ветвлений. На стадии подгрузки инструкции конвейера инструкций для проверки попадания в кэш трасс используется как текущий счетчик инструкций, так и состояние предсказателя ветвлений. Если попадание свершилось, линия трассы непосредственно подается на конвейер без необходимости опрашивать обычный кэш или основное ОЗУ. Кэш трасс подает машинные команды на вход конвейера, пока не кончится линия трассы, либо пока не произойдет ошибка предсказания в конвейере. В случае промаха кэш трасс начинает строить следующую линию трассы, загружая машинный код из кэша или из памяти. Похожие кэши трасс использовались в Pentium 4 для хранения декодированных микроопераций и микрокода, реализующего сложные x86-инструкции. См полный текст работы Smith, Rotenberg and Bennett’s paper в Citeseer. Многоуровневые кэшиОдной из проблем является фундаментальная проблема баланса между задержками кэша и интенсивностью попаданий. Большие кэши имеют более высокий процент попаданий но, вместе с тем, и большую задержку. Чтобы ослабить противоречие между этими двумя параметрами, большинство компьютеров использует несколько уровней кэша, когда после маленьких и быстрых кэшей находятся более медленные большие кэши Многоуровневые кэши обычно работают в последовательности от меньших кэшей к большим. Сначала происходит проверка наименьшего и наибыстрейшего кэша первого уровня, в случае попадания процессор продолжает работу на высокой скорости. Если меньший кэш дал промах, проверяется следующий, чуть больший и более медленный кэш второго уровня, и так далее, пока не будет запроса к основному ОЗУ. По мере того, как разница задержек между ОЗУ и быстрейшим кэшем увеличивается, в некоторых процессорах увеличивают количество уровней кэша. К примеру, Alpha 21164 в 1995 имела накристалльный кэш 3го уровня в 96 КБ; IBM POWER4 в 2001 имел до четырех кэшей L3 по 32 МБ на отдельных кристаллах, используемых совместно несколькими ядрами; Itanium 2 в 2003 имел 6 МБ кэш L3 на кристалле; Интеловский Xeon MP под кодом «Tulsa» в 2006 — 16 МБ кэша L3 на кристалле, общий на 2 ядра; АМДшный Phenom II в 2008 — до 6 МБ универсального L3 кэша; Intel Core i7 в 2008 — 8 МБ накристалльного кэша L3, являющимся инклюзивным и разделяемым между всеми ядрами. Польза от кэша L3 зависит от характера обращений программы в память. Наконец, с другой стороны иерархии памяти находится регистровый файл самого микропроцессора, который можно рассматривать как небольшой и самый быстрый кэш в системе со специальными свойствами. Подробнее см loop nest optimization. Регистровый файлы также могут иметь иерархию: Cray-1 имел 8 адресных «A»-регистров и 8 скалярных «S»-регистров общего назначения. Также машина содержала набор из 64 адресных «B» и 64 скалярных «T» регистров, обращение к которым было дольше, но все же значительно быстрее основной ОЗУ. Эти регистры были введены по причине отсутствия в машине кэша данных Эксклюзивность и инклюзивностьДля многоуровневых кешей требуется делать новые архитектурные решения. Например, в некотором процессоре могут потребовать, чтобы все данные, хранящиеся в кэше L1, хранились также и в кэше L2. Такие пары кэшей называют строго инклюзивными. Другие процессоры могут не иметь подобного требования, тогда кэши называются эксклюзивными — данные могут быть либо в L1, либо в L2 кэше, но никогда не могут быть одновременно в обоих. Пример кэшаПриведена схема кэшей ядра микропроцессоров AMD K8, на которой видны как специализированные кэши так и их многоуровневость. Ядро использует 4 различных специализированных кэша: кэш инструкций, TLB инструкций, TLB данных и кэш данных:
Также в этом ядре используются многоуровневые кэши: двухуровневые TLB инструкций и данных, и кэш второго уровня, унифицированный для работы как с кэшами данных и инструкций 1го уровня, так и для различных TLB. Кэш L2 является эксклюзивным для L1 данных и L1 инструкций, то есть каждый кэшированный 8-байтовый фрагмент может находиться либо в L1 инструкций, либо в L1 данных, либо в L2. Исключением могут быть лишь байты, составляющие записи PTE, которые могут находиться одновременно в TLB и в кэше данных во время обработки виртуального отображения со стороны ОС. В таком случае ОС отвечает за своевременный сброс TLB после обновления записей трансляции. … Просмотров: 8168
|