Интернет магазин китайских планшетных компьютеров |
|
Компьютеры - Сжатие без потерь - Сжатие и комбинаторика22 января 2011Оглавление: 1. Сжатие без потерь 2. Сжатие и комбинаторика 3. Техника сжатия без потерь 4. Методы сжатия без потерь 5. Примеры форматов и их реализаций Легко доказывается теорема.
Доказательство. Не ограничивая общности, можно предположить, что уменьшился файл A длины ровно N. Обозначим алфавит как Σ. Рассмотрим множество Впрочем, данная теорема нисколько не бросает тень на сжатие без потерь. Дело в том, что любой алгоритм сжатия можно модифицировать так, чтобы он увеличивал размер не более чем на 1 бит — так что несжимаемые фрагменты не приведут к бесконтрольному «раздуванию» архива. «Реальных» же файлов длины N намного меньше, чем 256 — например, маловероятно, чтобы буквосочетание «щы» встретилось в осмысленном тексте, а в оцифрованном звуке уровень не может за один сэмпл прыгнуть от 0 до 100 %. К тому же за счёт специализации алгоритмов на некоторый тип данных удаётся добиться высокой степени сжатия: так, применяющиеся в архиваторах универсальные алгоритмы сжимают звук примерно на треть, в то время как FLAC — в 2,5 раза. Большинство специализированных алгоритмов малопригодны для файлов «чужих» типов: например, звуковые данные плохо сжимаются алгоритмом, рассчитанным на тексты. Просмотров: 4600
|
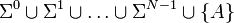 . В этом множестве
. В этом множестве 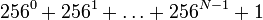 исходных файлов, в то время как сжатых не более чем
исходных файлов, в то время как сжатых не более чем 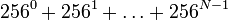 . Поэтому функция декомпрессии неоднозначна, противоречие. Теорема доказана.
. Поэтому функция декомпрессии неоднозначна, противоречие. Теорема доказана.